目标任务
实验项目
完成以下描述赋值语句SLR(1)文法语法制导生成中间代码四元式的过程。1
2
3
4
5G[A]: A→V=E
E→E+T∣E-T∣T
T→T*F∣T/F∣F
F→(E)∣i
V→i
设计说明
终结符号i为用户定义的简单变量,即标识符的定义。
设计要求
(1)构造文法的SLR(1)分析表,设计语法制导翻译过程,给出每一产生式对应的语义动作;
(2)设计中间代码四元式的结构;
(3)输入串应是词法分析的输出二元式序列,即某赋值语句“专题1”的输出结果,输出为赋值语句的四元式序列中间文件;
(4)设计两个测试用例(尽可能完备),并给出程序执行结果四元式序列。
实验过程
数据结构
在明确好编程思想后,首先需要确定下来的就是如何组织类及类成员,如何存储数据。
下面给出算符优先语法分析类class SLR的成员变量/函数及其设计说明:
类成员变量
| 成员变量 | 类型 | 备注 |
|---|---|---|
| start | str | 文法开始符号 |
| Vt | set() | 终结符号集合 |
| Vn | set() | 非终结符号集合 |
| V | set() | 文法全部符号集合,用于构造SLR分析表 |
| rule | dict{str: list[str]} | 文法产生式规则 |
| point | str | 即符号‘.’,用于构造项目集 |
| first | set() | 文法的first集,用于构造follow集 |
| follow | set() | 文法的follow集,用于解决冲突项目 |
| C | dict{int: dict{str:list[str]}} | 记录有效项目集规范族 |
| r | dict{int: dict{str:str}}} | 记录产生式序号,辅助生成action表中的r项 |
| action | dict{(int,str):str} | 记录SLR分析表中的action动作,包括‘S’和‘r’ |
| goto | dict{(int,str):int} | 记录SLR分析表中的goto动作,即记录待跳转的下一个项目集序号 |
类成员函数
| 成员函数 | 备注 |
|---|---|
| init(self, start, Vn, Vt, rule) | 类的构造函数,通过输入文法的开始符号、非终结符/终结符号集、产生式规则从而构造并返回SLR类 |
| get_first(self) | 构造first集合 |
| get_follow(self) | 构造follow集合 |
| op_start(self) | 构造有效项目集的第一步动作,即加入:‘.’+开始符号产生式 |
| op_closure(self,c_j) | 求c_j项目集的闭包 |
| op_go(self,i,x) | 实现Go(Ci ,x)函数功能 |
| judge(self,i) | 判断C[i]是否为终态,辅助构造有效项目集C |
| get_C(self) | 生成有效项目集规范族C |
| get_r(self) | 生成带序号的产生式,用于生成action表中的r部分 |
| get_action(self) | 构造分析表的action部分 |
| get_goto(self) | 构造分析表的goto部分 |
| compile(self, symbol, word, log) | 对输入语句进行语法分析,其中 symbol: 符号语句;word: 真实语句;log: 是否打印四元式 |
本次实验的重点在于下面几个成员函数的实现:
求c_j项目集的闭包
get_C(self): 自动生成有效项目集规范族C
get_action(self): 构造分析表的action部分
get_goto(self): 构造分析表的goto部分
compile(self, symbol, word, log): 对输入语句进行语法分析
求C[j]项目集的闭包
求C[j]项目集闭包,即实现closure(Cj)的功能,其算法如下:
$$
① C_i 的任何项目均属于closure(C_i)
$$
$$
② (重复)若A → α·X β(X∈V_n) ∈ closure(C_i) ,则X → ·λ ∈ closure(C_i)
$$
$$
③ C_i = closure(C_i)
$$
代码实现如下,上面三步在代码中有详细注释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25def op_closure(self,c_j):
#① C_i 的任何项目均属于closure(C_i)
closure_i = c_j
#② (重复)若A → α·X β(X∈V_n) ∈ closure(C_i) ,则X → ·λ ∈ closure(C_i)
while(True):
closure_i1=closure_i.copy()
key_list = list(closure_i.keys())
for A in key_list:
for aXb in closure_i[A]:
for j in range(len(aXb)-1):
if(aXb[j]==self.point and aXb[j+1] in self.Vn):
# 如何没有则新建一个key
if(aXb[j+1] not in closure_i.keys()):
closure_i.update({aXb[j + 1]:[]})
key_list.append(aXb[j + 1])
for l in rule[aXb[j+1]]:
temp = self.point+l
if(temp not in closure_i[aXb[j+1]]):
closure_i[aXb[j+1]].append(temp)
# 重复,直至 closure(Ci)不再增大.
if(closure_i != closure_i1):
closure_i1 = closure_i.copy()
else:
# ③ C_i = closure(C_i)
return closure_i
自动生成有效项目集规范族C
在SLR(1)分析过程中,前期准备中最重要的就是构建SLR(1)的有效项目集规范族C
根据生成算法,我们来对代码进行逐步实现
1.拓广文法,保证唯一初态.
1 | # 拓广文法 |
2.生成C0={S→ ·δ} ∪{S→ ·δ的闭包操作}
1 | # 生成C0={S→ ·δ} |
3.重复以下过程,直至C不再增大为止.
Ci读操作,生成Cj1,Cj2,…….Cjn
Cj1,Cj2,…….Cjn闭包操作(若其中某项目集已经存在就略去)
1 | i = 0 |
到此,该文法下的有效项目集规范族已被完全构建,看一下预览:
可以看到,拓广文法后产生的21个项目完全正确
构造分析表的action部分
SLR(1)文法的分析表包括action和Goto两个部分,这里先谈第一部分,即action部分的实现
action动作的添加主要分为三种情况:
1.若GO(Ci, a)=Cj a∈Vt, 置ACTION(i,a)=Sj
Sj:移进,把下一状态j和现输入符号a移入栈
2.若S→δ· ∈ Ck , (S为拓广文法开始符号) 置ACTION(k,#)=acc
acc:接受
3.若A→α·∈Ci , 且 a∈FOLLOW(A) , a∈Vt 置ACTION(i,a)=rj (A → α为第 j个产生式)
rj:归约,按第j产生式归约
所以我们的目的是,遍历文法Vt中的所有终结符号
在构造好的项目集C中找到对应情况下的(项目,符号)组合,为该组合添加对应动作
代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# 构造分析表的action部分
def get_action(self):
# 若GO(Ci, a)=Cj a∈Vt, 置ACTION(i,a)=Sj
for i in self.C.keys():
for a in self.Vt:
j = self.GO(i,a)
if(j!=-1):
self.action[(i,a)]='S'+str(j)
# 若A→α·∈Ci , 且 a∈FOLLOW(A)
# a∈Vt 置ACTION(i,a)=rj (A → α为第 j个产生式)
for i in self.C:
for A in self.C[i].keys():
for item in self.C[i][A]:
# 项目最后一个为点 '·'
if(item[-1] == self.point):
for a in self.follow[A]:
# 找到对应的规约产生式
for j in self.r.keys():
temp = {A:item[:-1]}
if(self.r[j] == temp):
self.action[(i,a)]='r'+str(j)
# 若S→δ·∈ Ck ,(S为拓广文法开始符号)
# 置ACTION(k,#)=acc
omiga = rule[self.start]+self.point
for k in self.C:
for key in self.C[k].keys():
if(key==self.start and omiga in self.C[k][key]):
self.action[(k,'#')]="acc"
构造分析表的Goto部分
Goto部分是在遍历文法Vn中的所有非终结符号时产生的动作,即状态S面临文法符号x时下一状态
Goto动作的添加仅对应一种情况:
若GO(Ci,A)=Cj , A∈Vn ,置GOTO(i,A)=j
代码实现如下:1
2
3
4
5
6
7
8# 构造分析表的goto部分
def get_goto(self):
# 若GO(Ci, A)=Cj A∈Vn, 置GOTO(i,A)=j
for i in self.C.keys():
for A in self.Vn:
j = self.GO(i, A)
if (j != -1):
self.goto[(i, A)] = j
到此,我们已经构造好了SLR(1)分析表的所有部分,对于该题文法下的分析表,预览如下:

可对比上面生成的项目集,结果完全正确!
语法分析
在SLR类构建完毕之后,下面我们便可以通过接收输入来进行语法分析过程。
控制输入
根据题干要求,输入参数应为词法分析器所输出的二元组,所以这里对分析函数的参数列表构建如下,其中,word代表真实符号,symbol代表根据真实符号所转化的定义符号:1
def compile(self, symbol, word, log)
举个例子,对于输入语句:X = A*(B+C)+D而言:1
2symbol : i=i*(i+i)+i
word : X=A*(B+C)+D
可以看出,symbol的作用在于进行语法分析,而word的作用在于生成四元式。
当然,这实现起来很简单,只需要在读如文件时控制读如组合即可,代码如下:1
2
3
4
5
6
7
8test_words = ""
test_symbol = ""
f = open("in2.0.txt",'r')
while(True):
t = f.readline().strip('\n')
if(t == ''): break
test_symbol += t[0]
test_words += t[-1]
对于如下格式的二元组输入:
可以看到这样的拼接结果:
SLR(1)分析
SLR(1)的分析过程与LR(0)相同,需要两个栈来辅助分析,分别是:状态栈、符号栈
分析过程如图: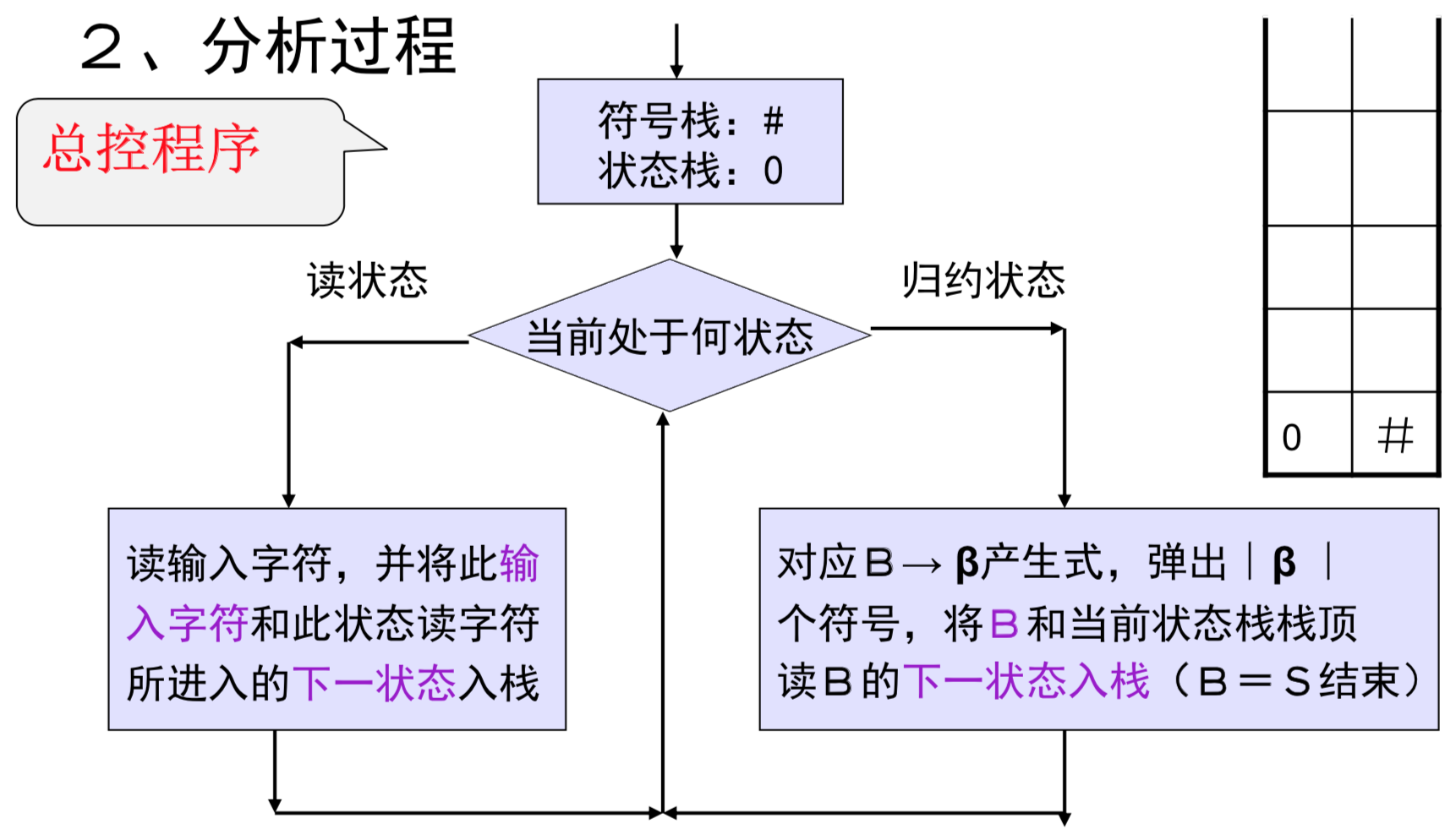
代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60# SLR(1)法分析
# symbol: 符号语句 word: 真实语句
def compile(self, symbol, word, log):
# 补充#
symbol+="##"
# 状态栈
state = ['0']
# 符号栈
charater = ['#']
#输入串下标
k=0
while(True):
state_now = eval(state[len(state)-1])
input_ch = symbol[k]
if ((state_now,input_ch) in self.action.keys()):
action = self.action[(state_now, input_ch)]
else:
action='-1'
if(action[0]=='S'):
#if(input_ch != '#'):
k = k+1
charater.append(input_ch)
state.append(action[1:])
continue
elif(action[0]=='r'):
# 规约动作r
r = {}
r = self.r[eval(action[1])]
# 规约长度
lenth = 0
# 规约终结符
substitude = ''
r_rule=''
for left in r.keys():
substitude = left
for right in r[left]:
r_rule+=right
for i in range(len(r_rule)):
charater.pop()
state.pop()
# 新规约终结符进符号栈
charater.append(substitude)
new_state = self.goto[(eval(state[len(state)-1]),substitude)]
state.append(str(new_state))
elif(action=='acc'):
return True
else:
return False
其中,substitute和r_rule记录了每次规约时所选用的产生式substitute -> r_rule
所以根据此,我们可以去匹配生成对应的四元式组。
由课上所学可知,运算赋值语句文法每次规约时产生的对应动作如下:

用代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48# 根据规约规则r_rule决定执行动作, log为分析开关
# 预定义.PLACE变量
if log == True:
E_place = []
F_place = []
V_place = []
T_place = []
t = 0 #temp计数器
# 添加至上段中的while(True)中
if log==True:
# ② A →V=E
if (substitude == 'A' and r_rule == "V=E"):
print("( =, "+E_place.pop()+", ,"+V_place.pop()+" )")
# ③ E(1)→E(2)+T
elif (substitude == 'E' and r_rule == "E+T"):
E1_place = "temp"+str(t)
t=t+1
print("( +, "+E_place.pop()+", "+T_place.pop()+", "+E1_place+" )")
E_place.append(E1_place)
# ④ E → T
elif (substitude == 'E' and r_rule == "T"):
E_place.append(T_place.pop())
# ⑤ T(1)→ T(2)*F
elif (substitude == 'T' and r_rule == "T*F"):
T1_place = "temp"+str(t)
t=t+1
print("( *, "+T_place.pop()+", "+F_place.pop()+", "+T1_place+" )")
T_place.append(T1_place)
# ⑥ T → F
elif (substitude == 'T' and r_rule == "F"):
T_place.append(F_place.pop())
# ⑦ F →(E)
elif (substitude == 'F' and r_rule == "(E)"):
F_place.append(E_place.pop())
# ⑧ F → i
elif (substitude == 'F' and r_rule == "i"):
F_place.append(word[k-1])
# ⑨ V →i
elif (substitude == 'V' and r_rule == "i"):
V_place.append(word[k-1])
这里需要注意的一点是如何区分诸如E(1)→E(2)+T规则中的(1)和(2)
我的解决方法为:用栈结构来存储各个place变量。
根据运算赋值文法的特点,后产生的E一定会被先规约用掉,所以用栈来模拟可以保证先产生的E不被后续的E所覆盖。
到此,本次实验的SLR类已经被完全构建完毕。
SLR类分析
测试
我们以语句:X=A*(B+C)+D为例
对其进行词法分析,首先得到二元组结果文件如下:
经过文件组织拼接后,调用函数1
slr.compile(symbol=test_symbol,word=test_words,log=True)
得到输出结果如下:
为了详细分析,通过适当调整输出来观测状态栈、符号栈的变化,结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82/Library/Frameworks/Python.framework/Versions/3.6/bin/python3.6 /Users/jiahaonan/Desktop/大三下/编译原理/算符优先/SLR.py
[状态栈]:['0']
[符号栈]:['#']
[状态栈]:['0', '3']
[符号栈]:['#', 'i']
[1]: V -> i
[状态栈]:['0', '2']
[符号栈]:['#', 'V']
[状态栈]:['0', '2', '5']
[符号栈]:['#', 'V', '=']
[状态栈]:['0', '2', '5', '10']
[符号栈]:['#', 'V', '=', 'i']
[2]: F -> i
[状态栈]:['0', '2', '5', '8']
[符号栈]:['#', 'V', '=', 'F']
[3]: T -> F
[状态栈]:['0', '2', '5', '7']
[符号栈]:['#', 'V', '=', 'T']
[状态栈]:['0', '2', '5', '7', '13']
[符号栈]:['#', 'V', '=', 'T', '*']
[状态栈]:['0', '2', '5', '7', '13', '9']
[符号栈]:['#', 'V', '=', 'T', '*', '(']
[状态栈]:['0', '2', '5', '7', '13', '9', '10']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'i']
[4]: F -> i
[状态栈]:['0', '2', '5', '7', '13', '9', '8']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'F']
[5]: T -> F
[状态栈]:['0', '2', '5', '7', '13', '9', '7']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'T']
[6]: E -> T
[状态栈]:['0', '2', '5', '7', '13', '9', '15']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E']
[状态栈]:['0', '2', '5', '7', '13', '9', '15', '11']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E', '+']
[状态栈]:['0', '2', '5', '7', '13', '9', '15', '11', '10']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E', '+', 'i']
[7]: F -> i
[状态栈]:['0', '2', '5', '7', '13', '9', '15', '11', '8']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E', '+', 'F']
[8]: T -> F
[状态栈]:['0', '2', '5', '7', '13', '9', '15', '11', '16']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E', '+', 'T']
[9]: E -> E+T
( +, B, C, temp0 )
[状态栈]:['0', '2', '5', '7', '13', '9', '15']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E']
[状态栈]:['0', '2', '5', '7', '13', '9', '15', '20']
[符号栈]:['#', 'V', '=', 'T', '*', '(', 'E', ')']
[10]: F -> (E)
[状态栈]:['0', '2', '5', '7', '13', '18']
[符号栈]:['#', 'V', '=', 'T', '*', 'F']
[11]: T -> T*F
( *, A, temp0, temp1 )
[状态栈]:['0', '2', '5', '7']
[符号栈]:['#', 'V', '=', 'T']
[12]: E -> T
[状态栈]:['0', '2', '5', '6']
[符号栈]:['#', 'V', '=', 'E']
[状态栈]:['0', '2', '5', '6', '11']
[符号栈]:['#', 'V', '=', 'E', '+']
[状态栈]:['0', '2', '5', '6', '11', '10']
[符号栈]:['#', 'V', '=', 'E', '+', 'i']
[13]: F -> i
[状态栈]:['0', '2', '5', '6', '11', '8']
[符号栈]:['#', 'V', '=', 'E', '+', 'F']
[14]: T -> F
[状态栈]:['0', '2', '5', '6', '11', '16']
[符号栈]:['#', 'V', '=', 'E', '+', 'T']
[15]: E -> E+T
( +, temp1, D, temp2 )
[状态栈]:['0', '2', '5', '6']
[符号栈]:['#', 'V', '=', 'E']
[16]: A -> V=E
( =, temp2, ,X )
[状态栈]:['0', '1']
[符号栈]:['#', 'A']
[状态栈]:['0', '1', '4']
[符号栈]:['#', 'A', '#']
True
Process finished with exit code 0
分析过程及四元式产生结果完全正确!
优势
- 本次代码编写采用了面向对象的编程思想,保证了SLR类的泛用性
- 只需要改变输入的符号集合及文法规则,即可对不同的满足SLR1文法的语句进行语法分析
- 程序能给出每一步的精确分析过程,并产生对应四元组
附录
1 |
|

