实验项目
完成以下描述赋值语句的LL(1)文法的递归下降分析程序1
2
3
4
5
6
7
8
9S→V=E
E→TE′
E′→ATE′|ε
T→FT′
T′→MFT′|ε
F→ (E)|i
A→+|-
M→*|/
V→i
设计说明
终结符号i为用户定义的简单变量,即标识符的定义
设计要求
(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;
(2)递归下降分析程序应能发现简单的语法错误;
(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果
设计思路
接收输入
词法分析器输出文件
由设计要求中的(1)可知,语法分析器所能接受的输入为词法分析器所输出的二元组
首先我们来回顾一下词法分析器所输出的二元组的格式:
可以看到,语句i=i+i)对应的词法分析输出二元组格式为:<number,token>的格式
number:编码数字
token:符号/字符串
显然,我们可以通过一个结构体来接受词法分析器所输入的二元组!
数据存储结构
我构造的结构体如下:1
2
3
4
5//记录词法分析器生成的二元组
typedef struct {
int num;
string token;
}two;
考虑到语句长度总是变化的,所以为了提高程序的鲁棒性,总的数据结构应定义为可变数组:1
2//记录全部的二元组
vector<two> text;
到此,数据储存结构的准备工作1已全部完成。
构造执行函数
根据递归下降分析的思想,我们首先需要对所有非终结符对应的产生式构造执行函数。
再者,根据设计要求,我们在进行字符匹配时仅使用编码two->num进行匹配即可
编码映射
在本题中所使用到的主要编码如下:
| 字符 | 编码 |
|---|---|
| # | -1 |
| id | 10 |
| = | 18 |
| + | 19 |
| - | 21 |
| * | 23 |
| / | 24 |
| ( | 27 |
| ) | 28 |
S()
对产生式:S→V=E,可以得到如下的递归调用流程。
由词法分析器的编码可知,match(18)中的18代表字符
=
")
E()
对产生式:E→TE′,可以得到如下的递归调用流程。")
E’()
对产生式:`E′→ATE′|ε,可以得到如下的递归调用流程。
由于产生式包含空动作
E′→ε,所以在程序执行时需要判断是否读到E’的follow集元素,
其中编码28代表字符),编码-1代表字符#。
")
T()
对产生式:T→FT′,可以得到如下的递归调用流程。")
T’()
对产生式:T′→MFT′|ε,可以得到如下的递归调用流程。
由于产生式包含空动作
T′→ε,所以在程序执行时需要判断是否读到E’的follow集元素,
其中编码19代表字符+,编码21代表字符-,编码28代表字符),编码-1代表字符#。
")
F()
对产生式:F→ (E)|i,可以得到如下的递归调用流程:
10代表用户定义标识符,27代表字符
(,28代表字符)
")
A()
对产生式:A→+|-,可以得到如下的递归调用流程:
19代表字符
+,21代表字符-
")
M()
对产生式:M→*|/,可以得到如下的递归调用流程:
23代表字符
*,24代表字符/
")
V()
对产生式:V→i,可以得到如下的递归调用流程:
10代表用户定义标识符
")
测试
正确用例
对于语句:1
i = i + i
编译结果为: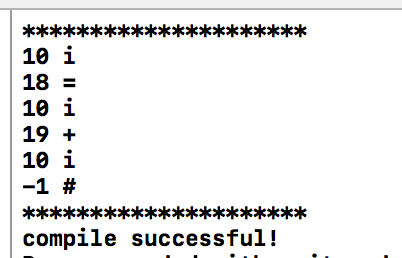
对于语句:1
i = i * (i/i)
编译结果为: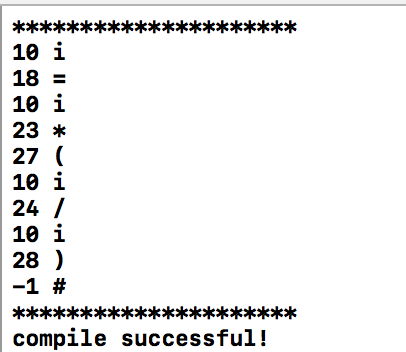
错误用例
对于语句:1
i = i + i )
编译结果为: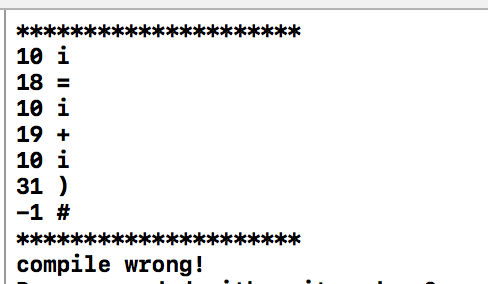
对于语句:1
i = i + -
编译结果为: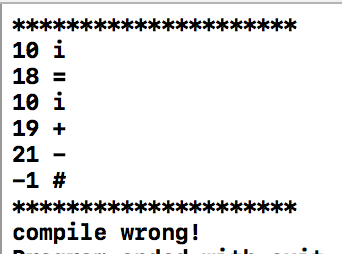
至此,该递归下降语法分析器已全部符合题目要求

