题目思考
本次选做题是制作一个文件名的识别程序,其可以识别诸如xx:xx.xx之类的文件名,具体题目要求如下:
某操作系统下合法的文件名规则为:device:name.extention,其中第一部分(device:)和第三部分(.extention)可缺省,若device、name和extention都是由字母组成,长度不限,但至少一位。
显然这样的题目要求与词法分析器和无符号数识别类似,按照之前的词法分析器程序的编写思路,首先来构造程序的状态转换图。
状态转换图
题目给出了文件名规则:device:name.extention,我们令d代表字母,则该规则可以转化为正则式表示为:d*:d+.d*,其中*和+分别代表0和1次及以上自重复。
从而可以得到如下的状态转换图:
其中:2状态的终结态代表device和extension均缺省的情况,4状态的终结态代表extension缺省的情况,6状态的终结态代表device缺省的情况。
数据流
根据上述状态转换图,可以拟定初步的编程数据流图如下:
子程序实现
显然,从数据流图中可以看到,功能实现的核心在于函数:int next_state(int current_state,char temp)
即根据现在状态以及下一个字符判断下一个状态,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69int next_state(int current_state,char temp){
int next=-1;
switch (current_state) {
case 1:{
if(isalpha(temp)){
next=2;
}
else{
next=-1;
}
break;
}
case 2:{
if(isalpha(temp)){
next=2;
}
else if(temp=='.'){
next=5;
}
else if(temp==':'){
next=3;
}
else{
next=-1;
}
break;
}
case 3:{
if(isalpha(temp)){
next=4;
}
else{
next=-1;
}
break;
}
case 4:{
if(isalpha(temp)){
next=4;
}
else if(temp=='.'){
next=5;
}
else{
next=-1;
}
break;
}
case 5:{
if(isalpha(temp)){
next=6;
}
else{
next=-1;
}
break;
}
case 6:{
if(isalpha(temp)){
next=6;
}
else{
next=-1;
}
break;
}
}
return next;
}
代码测试
在程序完备之后,我对程序选择了如下测试样例进行测试: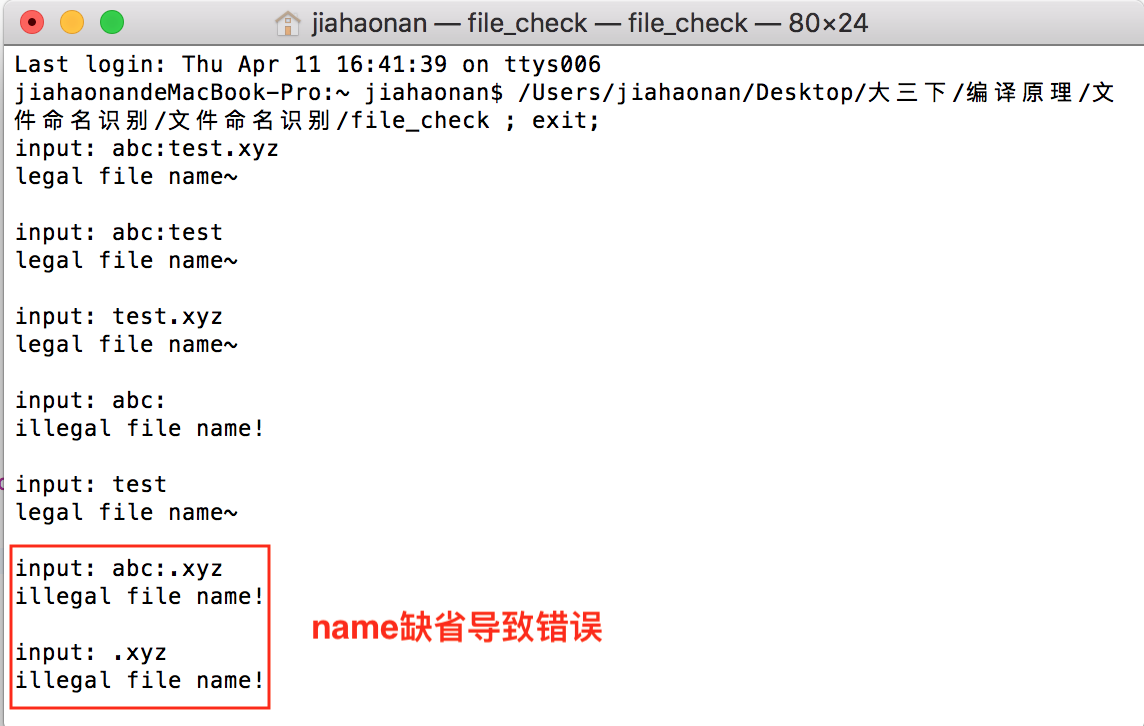

可以看到,凡是name缺省的错误文件命名均可以被识别。

