本次实验全部基于Ubuntu 16.04完成
代码托管于GitHub: https://github.com/hnjia00/OS2019
本次试验的内容核心在于对于信号量的理解和利用,通过信号量的合理配置从而使进程和线程的运行合乎逻辑。
实验目的
- 系统调用的进一步理解。
- 进程上下文切换。
- 同步的方法。
Q1.
通过fork的方式,产生4个进程P1,P2,P3,P4,每个进程打印输出自己的名字,例如P1输出“I am the process P1”。要求P1最先执行,P2、P3互斥执行,P4最后执行。通过多次测试验证实现是否正确。
A1.
首先需要理清楚进程的逻辑关系,为了使这四个进程满足题目要求的执行顺序,我在程序里使用了三组信号量,分别为sem1,sem2,sem3。
需要注明的是:
为了满足p1最先执行,p2和p3在其后等待,sem1设置了两个信号量,即sem1 = [0,0]。
p2等待p1的信号量sem1[0],p3等待p1的信号量sem1[1]从而达到在p1之后执行的要求。此外,为了满足p2和p3互斥执行,还定义了一个互斥信号量sem2 = 1,这样p2和p3在等待sem1之后还需要等待sem2以实现互斥执行的要求。
为了满足p4最后执行,即满足p4在p2和p3之后执行,sem3设置了两个信号量,即sem3 = [0,0]。其需要等待p2结束后产生的信号量sem3[0],以及等待p3结束后产生的信号量sem3[1],从而实现最后执行的要求,整体逻辑图如下:

在逻辑图实现之后,需要考虑进程的创建关系。
虽然一个父进程能创建若干个子进程,但是一个子进程只能对应一个父进程,也就是说进程的创建不能以信号量逻辑图为基础,因为P4不能对应两个父进程P2和P3。
所以在创建中各个进程所对应的父子关系与信号量逻辑图略有不同。
主程序代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65int main(int argc, char *argv[])
{
pid_t pid1, pid2, pid3;
int sem1, sem2, sem3;
sem1 = semget(1000, 2, 0666 | IPC_CREAT);//[0,0],保证p1最先
sem2 = semget(1001, 1, 0666 | IPC_CREAT);//[1],保证p2、p3互斥
sem3 = semget(1002, 2, 0666 | IPC_CREAT);//[0,0],保证p4最后
//信号量赋值
ushort init_arry[2] = {0, 0};
setSemValues(sem1, init_arry);
setSemValue(sem2, 0, 1);
setSemValues(sem3, init_arry);
pid1 = fork();
if (pid1 > 0)
{
pid2 = fork();
//p1
if (pid2 > 0)
{
printf("P1:I am P1\n");
printf("pid,ppid:%d,%d\n",getpid(),getppid() );
signal(sem1,0);
signal(sem1,1);
sleep(1);
}
//p4
if(pid2 == 0)
{
wait(sem3, 0);
wait(sem3, 1);
printf("P4:I am P4\n");
printf("pid,ppid:%d,%d\n",getpid(),getppid() );
}
}
if (pid1 == 0)
{
pid3 = fork();
//p2
if (pid3 > 0)
{
wait(sem1, 0);
wait(sem2, 0);
printf("P2:I am P2\n");
printf("pid,ppid:%d,%d\n",getpid(),getppid() );
signal(sem2, 0);
signal(sem3, 0);
sleep(1);
}
//p3
if (pid3 == 0)
{
wait(sem1, 1);
wait(sem2, 0);
printf("P3:I am P3\n" );
printf("pid,ppid:%d,%d\n",getpid(),getppid() );
signal(sem2, 0);
signal(sem3, 1);
}
}
return 0;
}
在第一题中,信号量的定义部分我使用了semget()函数,虽然其常用于定义一个单信号量,但我也用到了其定义信号量集的功能(如sem1和sem3),函数注释如下:1
2
3
4
5
6
7
8int semget(key_t key, int num_sems, int sem_flags):
功能描述:
创建一个新信号量或取得一个已有信号量
参数说明:
key:整数值,不相关的进程可以通过它访问一个信号量,它代表程序可能要使用的某个资源
num_sems:指定需要的信号量数目
sem_flags:一组标志,当想要当信号量不存在时创建一个新的信号量,可以和值IPC_CREAT做按位或操作
0666:创建了一个权限为666的信号量,每个人可读和可写
此外,代码中所用到的setSemValues(),setSemValue(),wait(),signal()的具体实现均已托管至GitHub,有兴趣可以进一步一探究竟!
代码的执行结果如图,可以看到,多次执行均能保证进程次序。
Q2.
火车票余票数ticketCount 初始值为1000,有一个售票线程,一个退票线程,各循环执行多次。添加同步机制,使得结果始终正确。要求多次测试添加同步机制前后的实验效果。(说明:为了更容易产生并发错误,可以在适当的位置增加一些pthread_yield(),放弃CPU,并强制线程频繁切换。)
A2.
从题目可以体会到,这是一个典型的生产者消费者问题,售票线程为消费者,退票线程为生产者,临界资源为火车票余票数ticketCount。
初步分析
进一步分析可以得知:
- 退票线程能够访问临界资源的条件为:火车票余量空间满足退票数目。
- 售票线程能够访问临界资源的条件为:火车票余量大于0.
有了以上思路后,可以通过设置两个信号量来实现上述功能,两个信号量的介绍如下:
- empty = 0:记录剩余空间
- full = 1000:记录剩余票数
初步实现
代码的实现逻辑如下:
为了保证代码和逻辑的鲁棒性,需要在关键代码部分增加pthread_yield()函数来测试代码,对pthread_yield()函数的解释为:
pthread_yield() causes the calling thread to relinquish the CPU.
The thread is placed at the end of the run queue for its static priority and another thread is scheduled to run.
即pthread_yield()使调用线程放弃CPU。该线程放在运行队列的末尾,以获得其静态优先级并计划运行另一个线程。
售票线程、退票线程的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43int ticketCount=1000;//剩余票数
int temp;
sem_t *empty = NULL;//记录剩余空间
sem_t *full = NULL;//记录剩余票数
int N_sell;//售票数
int N_return;//退票数
int pthread_yield(void);
//售票
void *Psell(){
int i=0;
for(;i<N_sell;i++){
sem_wait(full);
//售票进程关键代码
temp=ticketCount;
pthread_yield();
temp=temp-1;
pthread_yield();
ticketCount=temp;
//
printf("[Sell - %d]\n",i+1);
sem_post(empty);
}
printf("[Sell end: total sell:%d]\n",i);
}
//退票进程
void *Preturn(){
int i=0;
for(;i<N_return;i++){
sem_wait(empty);
//退票进程关键代码
temp=ticketCount;
pthread_yield();
temp=temp+1;
pthread_yield();
ticketCount=temp;
//
printf("{Return + %d}\n",i+1);
sem_post(full);
}
printf("{Return end: total return:%d}\n",i);
}
初步测试
对于售票数=30,退票数=7的测试,执行结果如图所示,可以看到在模拟售票30张退票7张时,程序的执行结果正确:
在小规模测试上获得正确结果之后,接下来我将测试级扩大到了10w级别,对于售票数=100000,退票数=99000的测试,程序的结果如下:
竟然得到了错误的结果!
出错分析
为了探究出错原因,我将pthread_yield()函数去掉重新执行了代码,这次程序的出了正确的结果:的执行结果")
纠其原因,尽管使用了生产消费者所常用的配套信号量,但仍然不足以克服pthread_yield函数所带来的线程切换。也就是说,尽管通过sem_wait(empty)能控制退票线程Preturn()访问临界区的的入口条件,但即使Preturn()进入了临界区,其也有可能被pthread_yield所强制切换到Psell()售票线程,从而导致临界区被两个线程同时访问,以至于临界资源ticketCount被错误修改!
所以,为了达到保护临界资源的目的,需要设置互斥信号量!从而保证任意适合只能有一个线程对临界资源进行访问修改。
二次修改
修改后的线程逻辑如下:
进而修改线程代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42sem_t *mutex = NULL;//互斥信号量
//售票
void *Psell(){
int i=0;
for(;i<N_sell;i++){
sem_wait(full);
//等待互斥信号
sem_wait(mutex);
//售票进程关键代码
temp=ticketCount;
//pthread_yield();
temp=temp-1;
//pthread_yield();
ticketCount=temp;
printf("[Sell - %d]\n",i+1);
sem_post(empty);
//释放互斥信号
sem_post(mutex);
}
printf("[Sell end: total sell:%d]\n",i);
}
//退票进程
void *Preturn(){
int i=0;
for(;i<N_return;i++){
sem_wait(empty);
//等待互斥信号
sem_wait(mutex);
//退票进程关键代码
temp=ticketCount;
pthread_yield();
temp=temp+1;
pthread_yield();
ticketCount=temp;
printf("{Return + %d}\n",i+1);
sem_post(full);
//释放互斥信号
sem_post(mutex);
}
printf("{Return end: total return:%d}\n",i);
}
正确执行
再次执行上次的测试用例,这次的执行结果为0,即售票-10w,退票+9.9w,初始+0.1w=0,完全正确!
Q3.
一个生产者一个消费者线程同步。设置一个线程共享的缓冲区, char buf[10]。一个线程不断从键盘输入字符到buf,一个线程不断的把buf的内容输出到显示器。要求输出的和输入的字符和顺序完全一致。(在输出线程中,每次输出睡眠一秒钟,然后以不同的速度输入测试输出是否正确)。要求多次测试添加同步机制前后的实验效果。
A3.
这是一个典型的生产者-消费者问题,思路与第二题相仿,需要两个信号量来辅助实现,信号量的使用情况如下:
- empty = 5:记录剩余空间
- full = 0:记录使用空间
要说明的一点是,为了便于测试debug和结果演示,我将char buf[10]修改为了int buf[5],一来是缩小规模可以更直观看到演示结果,二来使用int型数组也可以防止回车符的乱入。
由于逻辑与上一题相仿,仅仅是取消了互斥mutex,所以这里不做赘述。
代码实现
读入和输出线程的实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
int buf[N];
//信号量
sem_t *empty=NULL,*full=NULL;
//T1、T2分别代表输入输出的测试规模
int T1=15,T2=15;
//in:输入指针,out:输出指针
int in=0,out=0;
//输入线程
void *producer() {
int nextp;
while(T1--){
sem_wait(empty);
printf("%s\n","input: ");
scanf("%d",&nextp);
buf[in]=nextp;
in = (in+1)%N;
sem_post(full);
}
printf("%s\n", "[input]:over");
return NULL;
}
//输出线程
void *consumer() {
int nextc;
while(T2--){
sem_wait(full);
nextc=buf[out];
sleep(1);
printf("output:%d\n", nextc);
out = (out+1)%N;
sem_post(empty);
}
printf("%s\n", "[output]:over");
return NULL;
}
empty = sem_open("empty",O_CREAT,0666,5);//记录剩余空间
full = sem_open("full",O_CREAT,0666,0);//记录使用空间
测试用例
1 | 输入规模:T1=15 |
正常速度输入
对于正常的输入速度,程序的执行结果如下。可以看到,每一个输入下都匹配着正确的输出结果。

快速输入
对于快速的输入速度,程序的执行结果如下。
可以看到尽管输入提示语句input:看起来有一些“不合位置”,但在两个信号量empty和full的合理使用下,输入输出线程的进入条件会严格受控于缓冲区的剩余空间和已使用空间,十五个数字字符1~0,9~5全被成功输入并得以按顺序依次输出。
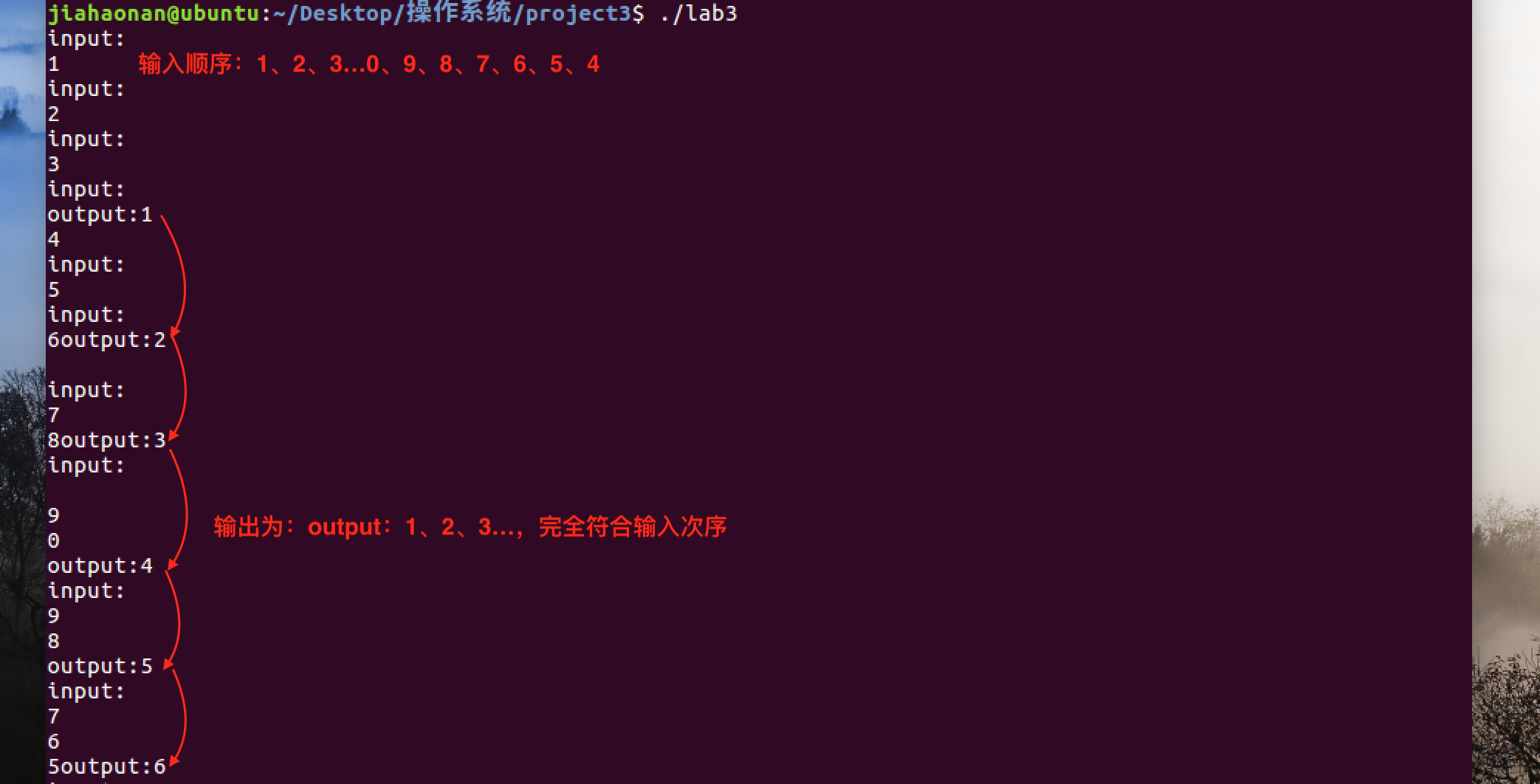

去同步机制输入
为了测试信号量的作用,这次测试将信号量去掉,重新进行快速输入,结果如下。
可以看到对于块长为5的缓冲区,在输入线程的指针in超过输出线程指针out的移动位置后,原先已经被输入但还未来得及输出的字符会被新的输入所覆盖,从而造成输出丢失,进而导致输出持续混乱
Q4.
a)通过实验测试,验证共享内存的代码中,receiver能否正确读出sender发送的字符串?如果把其中互斥的代码删除,观察实验结果有何不同?如果在发送和接收进程中打印输出共享内存地址,他们是否相同,为什么?
b)有名管道和无名管道通信系统调用是否已经实现了同步机制?通过实验验证,发送者和接收者如何同步的。比如,在什么情况下,发送者会阻塞,什么情况下,接收者会阻塞?
c)消息通信系统调用是否已经实现了同步机制?通过实验验证,发送者和接收者如何同步的。比如,在什么情况下,发送者会阻塞,什么情况下,接收者会阻塞?
A4.
a) 共享内存
功能测试
同时开启两个终端,分别启动receiver进程和sender进程,执行操作如下,在sender端键入字符串,且sender端以空格作为一段字符串的分隔标志,可以在receiver段得到sender端所输入的的字符串:
删除互斥
在删去信号量后,在接收端会发生输出混乱,具体表现如下:
receiver端不会等待sender端的输入情况,其会不加限制的重复输出共享内存中已有的内容:
重新开启进程后,上次程序所写在共享内存区内的字符串仍然会被重复输出:
观察地址
重新调回互斥,在sender进程和receiver进程分别添加语句1
2printf("\n[Sender] address:%p\n", shm_ptr);
printf("\n[Receiver] address:%p\n", shm_ptr);
实现打印共享内存的地址,可以观测到如下输出结果,两个进程的共享内存地址并不相同。
其原因为:sender进程和receiver进程实现了对共享内存shm_ptr的访问,shm_ptr的物理地址有且唯一,但在程序进程中所查询到的地址并不是shm_ptr的物理地址,而是shm_ptr向进程所映射的虚拟地址,所以这就造成了同一块物理地址在不同的进程中的打印值不同的结果。
即:共享内存在每个进程里的映射地址是不同的
b) 管道通信
无名管道
同步
无名管道的代码执行结果如图。
无名管道通过定义fd[2]文件描述符数组来实现消息同步:fd[0]描述只读,fd[1]描述只写,从而实现读写同步。
但值得注意的是,无名管道是半双工的,就是对于一个管道来讲,只能读,或者写。
无名管道只能在相关的,有共同祖先的进程间使用(即一般用户父子进程),而多进程用同一管道通信容易造成交叉读写的问题。
阻塞
在执行open,write,read等操作时会发生阻塞现象。
因为管道和文件一样,文件read函数以O_RDONLY方式打开也会阻塞,但是文件数据在本地,读取非常快,感觉不到阻塞,但是管道以O_RDONLY方式打开,会阻塞进程,read()函数会等待管道另一端写入数据,直到另一端关闭文件描述符。
更具体的,读写进程的阻塞可归类为下列几类情况:
| 读进程 | 写进程 | 管道无数据 | 管道有数据 |
|---|---|---|---|
| 阻塞 | return 0 | 返回数据 | |
| 阻塞 | 阻塞等待 | 读取数据 | |
| 阻塞 | 收到SIGPIPE信号,write返回-1 |
||
| 阻塞 | 写入数据 | 满则阻塞等待 |
有名管道
同步
有名管道的代码执行结果如图。
有名管道分别定义了两个进程来实现消息同步:
进程fifo_send实现了创建管道、向管道只写数据的功能。
进程fifo_rcv实现了查阅管道,从管道中只读数据的功能。
通过两个进程对同一管道的只读只写从而实现同步机制。

阻塞
有名管道的读写阻塞情况同无名管道。
此外,有名管道比无名管道还多一种阻塞情况:通信双方一方不存在则阻塞,如下图所示。
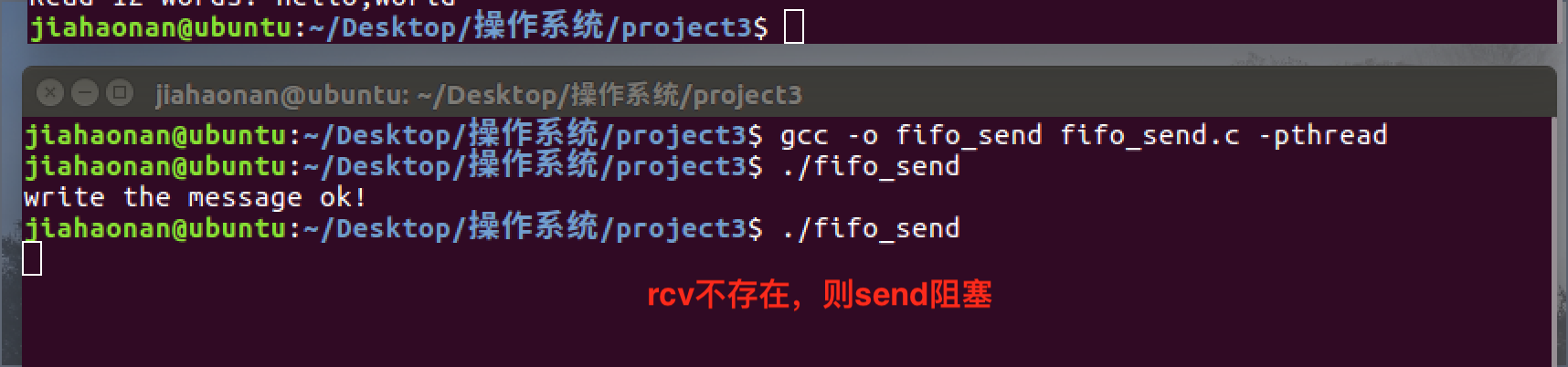

c) 消息队列
同步
消息队列的代码执行结果如图。
消息队列通过server端和client端的配合操作实现消息同步:
进程client中创建了两个进程,其中父进程用于接受键盘键入以及发送数据,子进程用于接收server的返回数据并实现输出。
进程server中等待接收client端发送的数据,当收到信息后,打印接收到的数据,并原样的返回client端。
以上流程通过两个struct msgbuf类型结构体sndBuf,rcvBuf来辅助实现。

阻塞
阻塞情况与管道类似,在队列中没有消息时读进程会阻塞,在队列中数据已满时写进程会阻塞。
Q5.
阅读Pintos操作系统,找到并阅读进程上下文切换的代码,说明实现的保存和恢复的上下文内容以及进程切换的工作流程。
A5.
代码阅读
有关关上下文切换的代码位于/threads/switch.h和/threads/switch.S中,这里首先介绍对两个代码的简略阅读。
switch.h
头文件代码如下:
汇编代码如下:
从CUR(正在运行的线程)切换到NEXT,NEXT也必须运行switch_threads(),在NEXT的上下文中返回CUR。这个函数通过假设我们切换到的线程也在运行switch_threads()来工作。因此,它所要做的就是在堆栈上保留一些寄存器,然后切换堆栈并恢复寄存器。作为切换堆栈的一部分,我们在CUR的线程结构中记录当前堆栈指针。
线程切换
如果一个线程用完了它的时间片,thread_tick就会调用该函数intr_yield_on_return。但是,此时不会产生下一个线程。相反,它修改一个标志,让中断处理程序知道,在从中断返回之前,它应该执行一个上下文切换到另一个线程。
于是,经过thread_tick和timer_interrupt回报,intr_handler将调用thread_yield,它将调用schedule。schedule选择要运行的下一个线程并调用一个函数switch_threads,在x86程序集中实现,带有两个参数:( cur指向thread 当前线程结构的指针,即被抢占next的指针)和(指向下一个thread结构的指针) 线程运行)。
所以,堆栈看起来像这样: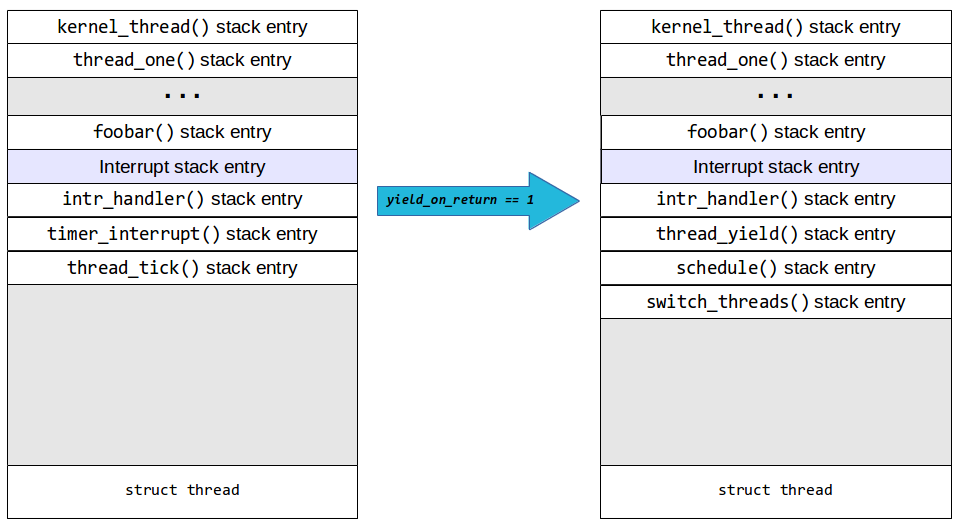
理解switch_threads的关键是要明白,如果切换到另一个线程,那么其他线程switch_threads在被抢占时也必须运行。实际上,一个自愿或非自愿地产生CPU的线程将始终具有类似于以下之一的堆栈:
switch_threads后面的所隐含的内容是,要切换到另一个线程,只需要切换堆栈(因为每个线程都保证switch_threads在被抢占的位置运行),我们只需更改esp值就可以做到这一点。
在调用之后switch_threads,堆栈的底部将如下所示:
switch_threads堆栈帧(0x0C00)的起始地址是任意的,没有深刻的意义。但是,显示的所有其他值将与从中switch_threads开始的堆栈帧0x0C00一致。
首先,switch_threads需要保存一些寄存器(这是x86架构所要求的):1
2
3
4pushl %ebx
pushl %ebp
pushl %esi
pushl %edi
堆栈结构如下:
接下来,switch.h将SWITCH_CUR和SWITCH_NEXT定义为堆栈帧中的cur和next的偏移量(20和24)。在x86中,表达式SWITCH_CUR(%esp)变为20(%esp),转换为内存地址esp+20cur。换句话说,这给了我们当前thread()的地址。类似的,SWITCH_NEXT(%esp)提供了next线程的地址 。
下面一段汇编代码保存当前线程的堆栈指针,并设置esp为指向要运行的下一个线程的(先前保存的)堆栈指针。1
2
3
4movl SWITCH_CUR (%esp ), %eax
movl %esp , (%eax ,%edx ,1 )
movl SWITCH_NEXT (%esp ), %ecx
movl (%ecx ,%edx ,1 ), %esp
在完成上述操作后,切换线程即完成,剩下的就是恢复之前推入堆栈的寄存器,然后返回switch_threads:1
2
3
4
5popl %edi
popl %esi
popl %ebp
popl %ebx
ret
进程切换
在理解清楚线程的切换机理后,进程切换也可以类比。
所谓进程切换,其只是线程切换和内核空间与用户空间之间切换的组合。基本上,当一个进程正在运行时,一个定时器中断将控制CPU回到内核,这将导致中断处理过程(最终导致调用thread_tick)。此时,如果我们抢占当前线程(及其关联的进程),我们将切换到不同的内核线程。如果此内核线程与进程关联,我们将切换回用户空间。
主要的区别是,切换到一个新的进程也将涉及调用process_activate从thread_schedule_tail(即运行功能之后switch_threads,但是从中断处理程序返回之前)。process_activate更新CPU的cr3寄存器以指向当前正在运行的进程的页面目录,并将值保存esp到TSS。
其中process_activate源码位于\userprog\process.c,TSS的源码位于\userprog\tss.c,如下所示:

参考文献
【1】Linux共享内存实现机制的详解 :https://www.jb51.net/article/118285.htm
【2】Linux 进程通信(无名管道):https://www.cnblogs.com/zhanggaofeng/p/5829801.html
【3】Linux进程间通信 – 管道(pipe):https://www.cnblogs.com/Jimmy1988/p/7553069.html
【4】Linux进程间通信 – 消息队列:https://www.cnblogs.com/Jimmy1988/p/7699351.html
【5】How does thread/process switching work in Pintos?:
https://uchicago-cs.github.io/mpcs52030/switch.html

